
To my greatest satisfaction, I’ve recently joined a new project. I started to read through the codebase before joining and at that stage, whenever I saw a possibility for a minor improvement, I raised a tiny pull request. One of my pet peeves is rooted in Sean Parent’s 2013 talk at GoingNative, Seasoning C++ where he advocated for no raw loops.
When I saw this loop, I started to think about how to replace it:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
#include <iostream>
#include <list>
#include <string>
#include <vector>
struct FromData {
// ...
std::string title;
int amount;
};
struct Widget {
// ...
std::list<FromData> data;
};
struct ToData {
// ...
std::string title;
int amount;
};
struct Response {
// ...
std::vector<ToData> data;
};
Response foo(Widget widget) {
std::vector<ToData> transformed_data;
for (const auto& element : widget.data) {
transformed_data.push_back(
{.title = element.title, .amount = element.amount * 42});
}
Response response;
// ...
response.data = transformed_data;
return response;
}
int main() {
Widget widget{.data = {
{"a", 1},
{"b", 2},
{"c", 1},
}};
auto r = foo(widget);
for (const auto& element : r.data) {
std::cout << "title: " << element.title << ", amount " << element.amount
<< '\n';
}
}
/*
title: a, amount 42
title: b, amount 84
title: c, amount 42
*/
Please note that the example is simplified and slightly changed so that it compiles on its own.
Let’s focus on foo, the rest is there just to make the example compilable.
It seems that we could use std::transform. But heck, we use C++20 we have ranges at our hands so let’s go with std::ranges::transform!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
#include <iostream>
#include <list>
#include <ranges>
#include <string>
#include <vector>
struct FromData {
// ...
std::string title;
int amount;
};
struct Widget {
// ...
std::list<FromData> data;
};
struct ToData {
// ...
std::string title;
int amount;
};
struct Response {
// ...
std::vector<ToData> data;
};
Response foo(Widget widget) {
const auto transformed_data = widget.data
| std::views::transform([](const auto& element) {
return ToData{
.title = element.title,
.amount = element.amount * 42
};
});
Response response;
// ...
response.data = {transformed_data.begin(), transformed_data.end()};
return response;
}
int main() {
Widget widget{.data = {
{"a", 1},
{"b", 2},
{"c", 1},
}};
auto r = foo(widget);
for (const auto& element : r.data) {
std::cout << "title: " << element.title << ", amount " << element.amount
<< '\n';
}
}
/*
title: a, amount 42
title: b, amount 84
title: c, amount 42
*/
We have no more raw loops, no more initialized then modified vectors, and the result is the same.
Is this better?
We don’t have to modify a vector that’s definitely better. But when I proposed such a change, one of my colleagues asked a question.
transformed_data became a view. When we populate response.data, do we actually copy all the elements of the view?
I couldn’t answer the question with confidence, hence this article.
I slightly updated both examples,and updated ToData to this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
struct ToData {
// ...
std::string title;
int amount;
ToData() {
std::cout << "ToData()\n";
}
ToData(std::string title, int amount) : title(title), amount(amount) {
std::cout << "ToData(std::string title, int amount)\n";
}
ToData(const ToData& other): title(other.title), amount(other.amount) {
std::cout << "ToData(const ToData& other)\n";
}
ToData& operator=(const ToData& other) {
std::cout << "ToData& operator=(const ToData& other)\n";
title = other.title;
amount = other.amount;
return *this;
}
ToData(ToData&& other)
: title(std::exchange(other.title, "")),
amount(std::exchange(other.amount, 0)) {
std::cout << "ToData(ToData&& other)\n";
}
ToData& operator=(ToData&& other) {
std::cout << "ToData& operator=(ToData&& other)\n";
title = std::exchange(other.title, "");
amount = std::exchange(other.amount, 0);
return *this;
}
};
I also had to remove the usage of designed initializers as ToData is no longer an aggregate.
The output for the original version using push_back is not particularly surprising.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
ToData(std::string title, int amount)
ToData(ToData&& other)
ToData(std::string title, int amount)
ToData(ToData&& other)
ToData(const ToData& other)
ToData(std::string title, int amount)
ToData(ToData&& other)
ToData(const ToData& other)
ToData(const ToData& other)
writing response.data
ToData(const ToData& other)
ToData(const ToData& other)
ToData(const ToData& other)
wrote response.data
title: a, amount 42
title: b, amount 84
title: c, amount 42
In the for loop, we construct ToData and move it, and there is also a copy construction. Before actually copying the data.
On the other hand, for the version using ranges, the output is shorter and different!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
filling response.data
ToData(std::string title, int amount)
ToData(ToData&& other)
ToData(std::string title, int amount)
ToData(ToData&& other)
ToData(const ToData& other)
ToData(std::string title, int amount)
ToData(ToData&& other)
ToData(const ToData& other)
ToData(const ToData& other)
filled1 response.data
title: a, amount 42
title: b, amount 84
title: c, amount 42
Nothing actually happens within the transformation pipeline! Everything is happening lazily when we use the results of the pipeline and actually construct a vector. Then we have fewer calls than we had in the original version. Seemingly, far the ranges version has an advantage!
But we all know that the original version is not optional even with a raw loop. Let’s use emplace_back! Oh and we also forgot about calling std::vector<T>::reserve to avoid reallocations! Here is the code producing the below output.
1
2
3
4
5
6
7
8
9
10
11
ToData(std::string title, int amount)
ToData(std::string title, int amount)
ToData(std::string title, int amount)
writing response.data
ToData(const ToData& other)
ToData(const ToData& other)
ToData(const ToData& other)
wrote response.data
title: a, amount 42
title: b, amount 84
title: c, amount 42
Now the raw loop version has an advantage! In this version, for each item, we have a constructor and a copy while in the ranges version, we also have an extra move!
Note that since C++23, you can also use
std::ranges::to<std::vector<Todata>>to construct the finalvector, but it didn’t result in any difference in terms of the number of special member function calls.
Is that so bad? Probably not. Move operations are cheap, that’s why they were introduced! Probably this is just an acceptable price to pay for more readable code. But our “more readable code” also features a lambda so let’s just say that we have assumptions.
Let’s also run benchmarks.
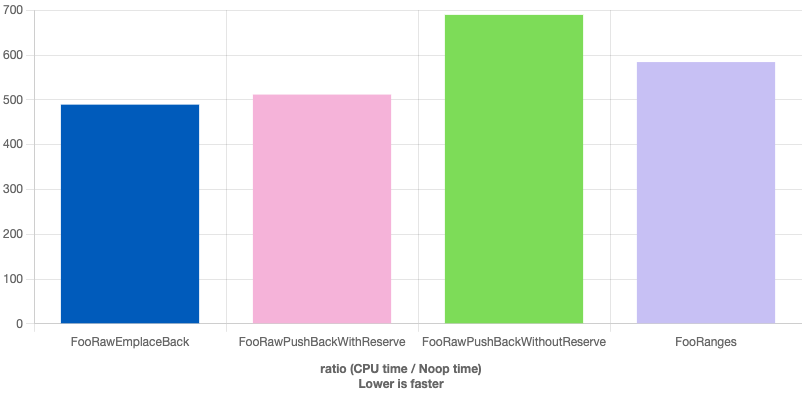
Based on Quick Bench, the enhanced raw loop version is about 20% faster on Clang than the raw loop version. The results are slightly different with GCC, but the raw loop version is still 10% faster. It’s also worth noting that the original version with a push_back and without the reserve is 20-30% slower than the other two versions! By adding the reserve but still using push_back, the code is between the ranges and the raw loop with emplace_back version.
What does this mean in real life?
It depends. You must measure. Don’t forget about Amdahl’s law which says that “the overall performance improvement gained by optimizing a single part of a system is limited by the fraction of time that the improved part is actually used.”
If this happens to be a bottleneck, use the emplace_back version without hesitation and don’t forget about reserving enough space in memory for all the elements.
I think you have no reason to use the push_back version and definitely not without calling reserve.
Otherwise, if you write code where you also do some network calls or read from the database or from the filesystem, these differences are negligible and you should go with the version that you find the most readable.
That’s up to you.
Conclusion
Using ranges or algorithms has several advantages over raw loops, notably readability. On the other hand, as we’ve just seen, sheer performance is not necessarily among those advantages. Using ranges can be slightly slower than a raw loop version. But that’s not necessarily a problem, it really depends on your use case. Most probably it won’t make a bit difference.
Connect deeper
If you liked this article, please
- hit on the like button,
- subscribe to my newsletter